
Design
When Technology Takes Over
Is AI Stripping Creativity from Architecture? The Dangers of Algorithm-Driven Design

Design
AI companies depend on large amounts of data to train their language models. To create an AI image generation tool like Midjourney or OpenArt, companies need to have vast repositories of imagery to work from, So often what they do is utilise AI training datasets like this one from LAION-5B. Companies like LAION.ai scrape the web to extract data at scale for their collections. Companies have utilised images (unlawfully) from their competitors’ sites for years but what we’re talking about here is different for two reasons:
Scraping happens at scale: A human being taking, using or scraping content or images is a slow arduous process. What we’re talking about here is large scale scraping of entire sites and entire collections automatically day after day.
Historically if someone right clicked and saved your images, there was a limit to the damage they could do. They could use them on their own sites, or the sites of suppliers or competitors or publish them without acknowledging copyright . . but there was a limit. What we’re talking about here with large scale scraping for AI models, is the large scale theft of your images to be fed into the machine to enable others to create derivative works directly from your IP.
What is web scraping? Here’s an explanation
During another one of my deep dives down another delightful OSINT rabbit hole, I came across the site Have I been trained? which enables you to search for your own work or imagery in the popularAI training datasets and see if a company has used your imagery in the training of any large language models (LLM).
In a 2020 article by Tom Waterman you can find here, a US court ruling (relating to Linkedin’s request to prevent an analytics company from scraping its data) is as Tom suggests:
“ a historic moment in the data privacy and data regulation era. It showed that any data that is publicly available and not copyrighted is fair game for web crawlers.”
The theory goes that as long as the data scraped is publicly available, web crawlers can utilise that data as long as they themselves don’t post the content. The example Tom gives . . is that a crawler could scrape Youtube video metadata, so long as they don’t post the videos themselves which are subject to copyright.
However a 2022 US lawsuit profiled in The New Yorker which covers a new class action suit brought by a Tennessee artist, suggests that every image that a generative tool produces “is an infringing, deriative work”.
And this gets worse, in 2022 we saw an artist who found private medical photos had been scraped and used in an AI training data set. We’re not talking about a small problem here and it’s not limited to creative IP.
In July of this year, OpenAI openly admitted their bot (GPTbot )is being used to scrape and collect online content for AI model training. The next version - GPT-5, will likely be trained on the data scraped up by this bot.
Having worked in the architectural product game for a long time at Eco Outdoor, I did a quick search and found that hundreds of their images are being used by LAION-5B as training data.

I then did a search of a friend of mine Pete Stutchbury and found that he too, was subject to crawlers scraping a large amount of his creative project photography, albeit mostly from design publishers’ media platforms rather than his own website.
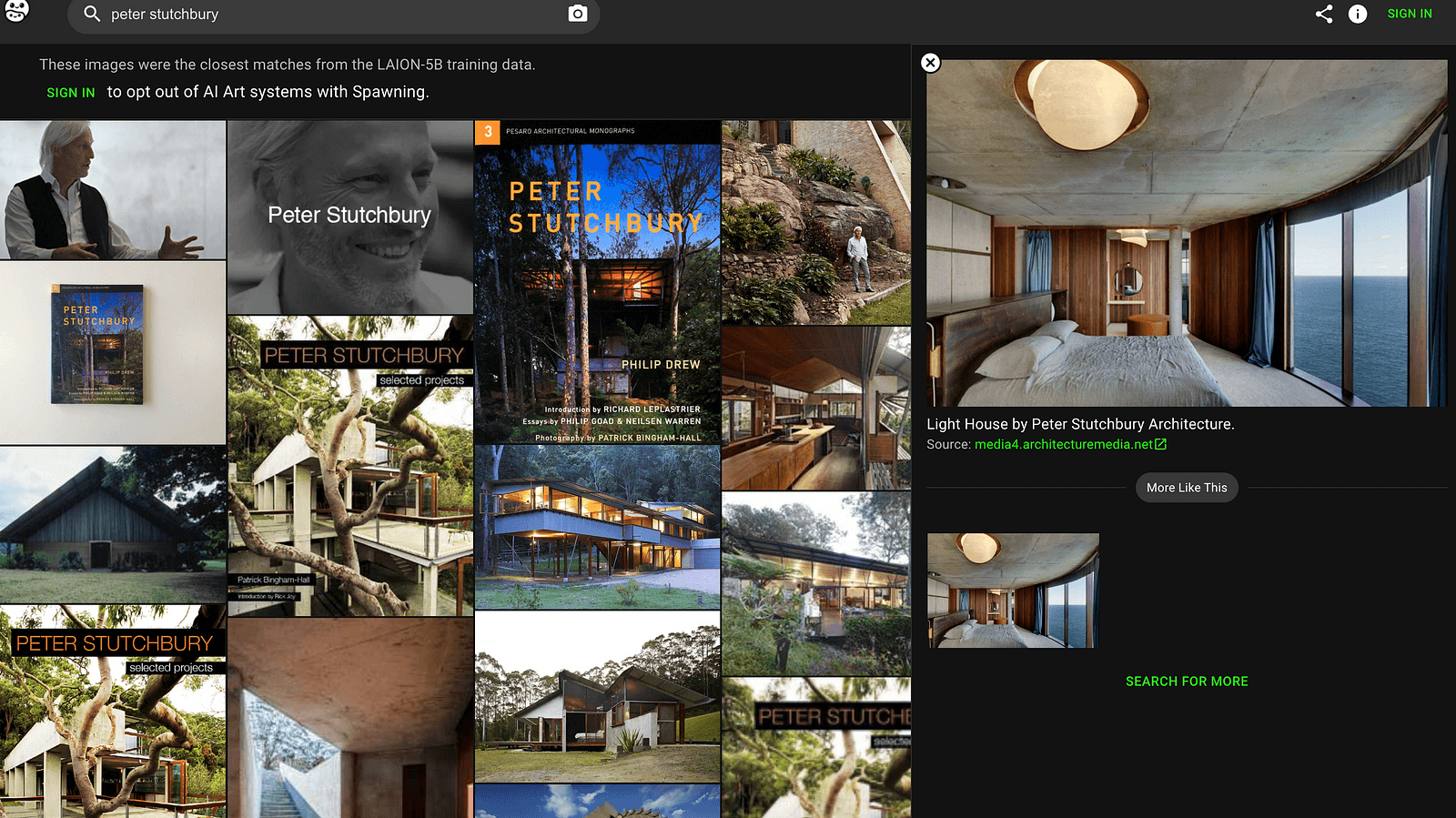
Now the decoupling of metadata being utilised vs using the actual content gets blurry here; as unlike the youtube example, the imagery these crawlers are scraping is copyrighted and belongs to both Pete (and potentially to the media platforms / photographers who took the photos).
Don’t get me wrong . . I’m not a technophobe, quite the opposite in fact. I was an early Midjourney user and love the creative freedom it offers BUT and there’s a big but . . . for people like Pete and in fact any other architect (replace architect with industrial designer, interior designer and so forth and you get the picture). When the creative products, the images of their signature works designed, built and crafted over many years, is being fed into an AI training data set . . . what we’ll see is over time, an enormous increase in derivative works and derivative references which are themselves, completely disconnected from their creators (and owners). The implications of this are deep and wide from the loss of artistic integrity, creative ownership and sovereignty to the dissolution of intellectual property rights and the monopolisation of creativity by big tech.
I’m no digital genius but presumably there are things web companies can do to reduce the risk or ease of crawlers scraping their sites. A quick search reveals a few recent 2023 articles that might provide a start point:
How to block OpenAI’s new AI-training web crawler from ingesting your data
Major websites block AI crawlers from scraping their content
We need to do more. The regulation simply cannot keep pace with the evolving technology and many aren't thinking about the ramifications every time they press /imagine on their midjourney engine. So what does this mean for the future of our creative industries? We need to be talking about this and big tech (and the platforms that feed of them) need to be held accountable.
What about the responsibilities of the personal user? Not a conversation we seem ready to have. Yet.
AI companies depend on large amounts of data to train their language models. To create an AI image generation tool like Midjourney or OpenArt, companies need to have vast repositories of imagery to work from, So often what they do is utilise AI training datasets like this one from LAION-5B. Companies like LAION.ai scrape the web to extract data at scale for their collections. Companies have utilised images (unlawfully) from their competitors’ sites for years but what we’re talking about here is different for two reasons:
Scraping happens at scale: A human being taking, using or scraping content or images is a slow arduous process. What we’re talking about here is large scale scraping of entire sites and entire collections automatically day after day.
Historically if someone right clicked and saved your images, there was a limit to the damage they could do. They could use them on their own sites, or the sites of suppliers or competitors or publish them without acknowledging copyright . . but there was a limit. What we’re talking about here with large scale scraping for AI models, is the large scale theft of your images to be fed into the machine to enable others to create derivative works directly from your IP.
What is web scraping? Here’s an explanation
During another one of my deep dives down another delightful OSINT rabbit hole, I came across the site Have I been trained? which enables you to search for your own work or imagery in the popularAI training datasets and see if a company has used your imagery in the training of any large language models (LLM).
In a 2020 article by Tom Waterman you can find here, a US court ruling (relating to Linkedin’s request to prevent an analytics company from scraping its data) is as Tom suggests:
“ a historic moment in the data privacy and data regulation era. It showed that any data that is publicly available and not copyrighted is fair game for web crawlers.”
The theory goes that as long as the data scraped is publicly available, web crawlers can utilise that data as long as they themselves don’t post the content. The example Tom gives . . is that a crawler could scrape Youtube video metadata, so long as they don’t post the videos themselves which are subject to copyright.
However a 2022 US lawsuit profiled in The New Yorker which covers a new class action suit brought by a Tennessee artist, suggests that every image that a generative tool produces “is an infringing, deriative work”.
And this gets worse, in 2022 we saw an artist who found private medical photos had been scraped and used in an AI training data set. We’re not talking about a small problem here and it’s not limited to creative IP.
In July of this year, OpenAI openly admitted their bot (GPTbot )is being used to scrape and collect online content for AI model training. The next version - GPT-5, will likely be trained on the data scraped up by this bot.
Having worked in the architectural product game for a long time at Eco Outdoor, I did a quick search and found that hundreds of their images are being used by LAION-5B as training data.
I then did a search of a friend of mine Pete Stutchbury and found that he too, was subject to crawlers scraping a large amount of his creative project photography, albeit mostly from design publishers’ media platforms rather than his own website.
Now the decoupling of metadata being utilised vs using the actual content gets blurry here; as unlike the youtube example, the imagery these crawlers are scraping is copyrighted and belongs to both Pete (and potentially to the media platforms / photographers who took the photos).
Don’t get me wrong . . I’m not a technophobe, quite the opposite in fact. I was an early Midjourney user and love the creative freedom it offers BUT and there’s a big but . . . for people like Pete and in fact any other architect (replace architect with industrial designer, interior designer and so forth and you get the picture). When the creative products, the images of their signature works designed, built and crafted over many years, is being fed into an AI training data set . . . what we’ll see is over time, an enormous increase in derivative works and derivative references which are themselves, completely disconnected from their creators (and owners). The implications of this are deep and wide from the loss of artistic integrity, creative ownership and sovereignty to the dissolution of intellectual property rights and the monopolisation of creativity by big tech.
I’m no digital genius but presumably there are things web companies can do to reduce the risk or ease of crawlers scraping their sites. A quick search reveals a few recent 2023 articles that might provide a start point:
How to block OpenAI’s new AI-training web crawler from ingesting your data
Major websites block AI crawlers from scraping their content
We need to do more. The regulation simply cannot keep pace with the evolving technology and many aren't thinking about the ramifications every time they press /imagine on their midjourney engine. So what does this mean for the future of our creative industries? We need to be talking about this and big tech (and the platforms that feed of them) need to be held accountable.
What about the responsibilities of the personal user? Not a conversation we seem ready to have. Yet.
AI companies depend on large amounts of data to train their language models. To create an AI image generation tool like Midjourney or OpenArt, companies need to have vast repositories of imagery to work from, So often what they do is utilise AI training datasets like this one from LAION-5B. Companies like LAION.ai scrape the web to extract data at scale for their collections. Companies have utilised images (unlawfully) from their competitors’ sites for years but what we’re talking about here is different for two reasons:
Scraping happens at scale: A human being taking, using or scraping content or images is a slow arduous process. What we’re talking about here is large scale scraping of entire sites and entire collections automatically day after day.
Historically if someone right clicked and saved your images, there was a limit to the damage they could do. They could use them on their own sites, or the sites of suppliers or competitors or publish them without acknowledging copyright . . but there was a limit. What we’re talking about here with large scale scraping for AI models, is the large scale theft of your images to be fed into the machine to enable others to create derivative works directly from your IP.
What is web scraping? Here’s an explanation
During another one of my deep dives down another delightful OSINT rabbit hole, I came across the site Have I been trained? which enables you to search for your own work or imagery in the popularAI training datasets and see if a company has used your imagery in the training of any large language models (LLM).
In a 2020 article by Tom Waterman you can find here, a US court ruling (relating to Linkedin’s request to prevent an analytics company from scraping its data) is as Tom suggests:
“ a historic moment in the data privacy and data regulation era. It showed that any data that is publicly available and not copyrighted is fair game for web crawlers.”
The theory goes that as long as the data scraped is publicly available, web crawlers can utilise that data as long as they themselves don’t post the content. The example Tom gives . . is that a crawler could scrape Youtube video metadata, so long as they don’t post the videos themselves which are subject to copyright.
However a 2022 US lawsuit profiled in The New Yorker which covers a new class action suit brought by a Tennessee artist, suggests that every image that a generative tool produces “is an infringing, deriative work”.
And this gets worse, in 2022 we saw an artist who found private medical photos had been scraped and used in an AI training data set. We’re not talking about a small problem here and it’s not limited to creative IP.
In July of this year, OpenAI openly admitted their bot (GPTbot )is being used to scrape and collect online content for AI model training. The next version - GPT-5, will likely be trained on the data scraped up by this bot.
Having worked in the architectural product game for a long time at Eco Outdoor, I did a quick search and found that hundreds of their images are being used by LAION-5B as training data.
I then did a search of a friend of mine Pete Stutchbury and found that he too, was subject to crawlers scraping a large amount of his creative project photography, albeit mostly from design publishers’ media platforms rather than his own website.
Now the decoupling of metadata being utilised vs using the actual content gets blurry here; as unlike the youtube example, the imagery these crawlers are scraping is copyrighted and belongs to both Pete (and potentially to the media platforms / photographers who took the photos).
Don’t get me wrong . . I’m not a technophobe, quite the opposite in fact. I was an early Midjourney user and love the creative freedom it offers BUT and there’s a big but . . . for people like Pete and in fact any other architect (replace architect with industrial designer, interior designer and so forth and you get the picture). When the creative products, the images of their signature works designed, built and crafted over many years, is being fed into an AI training data set . . . what we’ll see is over time, an enormous increase in derivative works and derivative references which are themselves, completely disconnected from their creators (and owners). The implications of this are deep and wide from the loss of artistic integrity, creative ownership and sovereignty to the dissolution of intellectual property rights and the monopolisation of creativity by big tech.
I’m no digital genius but presumably there are things web companies can do to reduce the risk or ease of crawlers scraping their sites. A quick search reveals a few recent 2023 articles that might provide a start point:
How to block OpenAI’s new AI-training web crawler from ingesting your data
Major websites block AI crawlers from scraping their content
We need to do more. The regulation simply cannot keep pace with the evolving technology and many aren't thinking about the ramifications every time they press /imagine on their midjourney engine. So what does this mean for the future of our creative industries? We need to be talking about this and big tech (and the platforms that feed of them) need to be held accountable.
What about the responsibilities of the personal user? Not a conversation we seem ready to have. Yet.
AI companies depend on large amounts of data to train their language models. To create an AI image generation tool like Midjourney or OpenArt, companies need to have vast repositories of imagery to work from, So often what they do is utilise AI training datasets like this one from LAION-5B. Companies like LAION.ai scrape the web to extract data at scale for their collections. Companies have utilised images (unlawfully) from their competitors’ sites for years but what we’re talking about here is different for two reasons:
Scraping happens at scale: A human being taking, using or scraping content or images is a slow arduous process. What we’re talking about here is large scale scraping of entire sites and entire collections automatically day after day.
Historically if someone right clicked and saved your images, there was a limit to the damage they could do. They could use them on their own sites, or the sites of suppliers or competitors or publish them without acknowledging copyright . . but there was a limit. What we’re talking about here with large scale scraping for AI models, is the large scale theft of your images to be fed into the machine to enable others to create derivative works directly from your IP.
What is web scraping? Here’s an explanation
During another one of my deep dives down another delightful OSINT rabbit hole, I came across the site Have I been trained? which enables you to search for your own work or imagery in the popularAI training datasets and see if a company has used your imagery in the training of any large language models (LLM).
In a 2020 article by Tom Waterman you can find here, a US court ruling (relating to Linkedin’s request to prevent an analytics company from scraping its data) is as Tom suggests:
“ a historic moment in the data privacy and data regulation era. It showed that any data that is publicly available and not copyrighted is fair game for web crawlers.”
The theory goes that as long as the data scraped is publicly available, web crawlers can utilise that data as long as they themselves don’t post the content. The example Tom gives . . is that a crawler could scrape Youtube video metadata, so long as they don’t post the videos themselves which are subject to copyright.
However a 2022 US lawsuit profiled in The New Yorker which covers a new class action suit brought by a Tennessee artist, suggests that every image that a generative tool produces “is an infringing, deriative work”.
And this gets worse, in 2022 we saw an artist who found private medical photos had been scraped and used in an AI training data set. We’re not talking about a small problem here and it’s not limited to creative IP.
In July of this year, OpenAI openly admitted their bot (GPTbot )is being used to scrape and collect online content for AI model training. The next version - GPT-5, will likely be trained on the data scraped up by this bot.
Having worked in the architectural product game for a long time at Eco Outdoor, I did a quick search and found that hundreds of their images are being used by LAION-5B as training data.
I then did a search of a friend of mine Pete Stutchbury and found that he too, was subject to crawlers scraping a large amount of his creative project photography, albeit mostly from design publishers’ media platforms rather than his own website.
Now the decoupling of metadata being utilised vs using the actual content gets blurry here; as unlike the youtube example, the imagery these crawlers are scraping is copyrighted and belongs to both Pete (and potentially to the media platforms / photographers who took the photos).
Don’t get me wrong . . I’m not a technophobe, quite the opposite in fact. I was an early Midjourney user and love the creative freedom it offers BUT and there’s a big but . . . for people like Pete and in fact any other architect (replace architect with industrial designer, interior designer and so forth and you get the picture). When the creative products, the images of their signature works designed, built and crafted over many years, is being fed into an AI training data set . . . what we’ll see is over time, an enormous increase in derivative works and derivative references which are themselves, completely disconnected from their creators (and owners). The implications of this are deep and wide from the loss of artistic integrity, creative ownership and sovereignty to the dissolution of intellectual property rights and the monopolisation of creativity by big tech.
I’m no digital genius but presumably there are things web companies can do to reduce the risk or ease of crawlers scraping their sites. A quick search reveals a few recent 2023 articles that might provide a start point:
How to block OpenAI’s new AI-training web crawler from ingesting your data
Major websites block AI crawlers from scraping their content
We need to do more. The regulation simply cannot keep pace with the evolving technology and many aren't thinking about the ramifications every time they press /imagine on their midjourney engine. So what does this mean for the future of our creative industries? We need to be talking about this and big tech (and the platforms that feed of them) need to be held accountable.
What about the responsibilities of the personal user? Not a conversation we seem ready to have. Yet.
AI companies depend on large amounts of data to train their language models. To create an AI image generation tool like Midjourney or OpenArt, companies need to have vast repositories of imagery to work from, So often what they do is utilise AI training datasets like this one from LAION-5B. Companies like LAION.ai scrape the web to extract data at scale for their collections. Companies have utilised images (unlawfully) from their competitors’ sites for years but what we’re talking about here is different for two reasons:
Scraping happens at scale: A human being taking, using or scraping content or images is a slow arduous process. What we’re talking about here is large scale scraping of entire sites and entire collections automatically day after day.
Historically if someone right clicked and saved your images, there was a limit to the damage they could do. They could use them on their own sites, or the sites of suppliers or competitors or publish them without acknowledging copyright . . but there was a limit. What we’re talking about here with large scale scraping for AI models, is the large scale theft of your images to be fed into the machine to enable others to create derivative works directly from your IP.
What is web scraping? Here’s an explanation
During another one of my deep dives down another delightful OSINT rabbit hole, I came across the site Have I been trained? which enables you to search for your own work or imagery in the popularAI training datasets and see if a company has used your imagery in the training of any large language models (LLM).
In a 2020 article by Tom Waterman you can find here, a US court ruling (relating to Linkedin’s request to prevent an analytics company from scraping its data) is as Tom suggests:
“ a historic moment in the data privacy and data regulation era. It showed that any data that is publicly available and not copyrighted is fair game for web crawlers.”
The theory goes that as long as the data scraped is publicly available, web crawlers can utilise that data as long as they themselves don’t post the content. The example Tom gives . . is that a crawler could scrape Youtube video metadata, so long as they don’t post the videos themselves which are subject to copyright.
However a 2022 US lawsuit profiled in The New Yorker which covers a new class action suit brought by a Tennessee artist, suggests that every image that a generative tool produces “is an infringing, deriative work”.
And this gets worse, in 2022 we saw an artist who found private medical photos had been scraped and used in an AI training data set. We’re not talking about a small problem here and it’s not limited to creative IP.
In July of this year, OpenAI openly admitted their bot (GPTbot )is being used to scrape and collect online content for AI model training. The next version - GPT-5, will likely be trained on the data scraped up by this bot.
Having worked in the architectural product game for a long time at Eco Outdoor, I did a quick search and found that hundreds of their images are being used by LAION-5B as training data.
I then did a search of a friend of mine Pete Stutchbury and found that he too, was subject to crawlers scraping a large amount of his creative project photography, albeit mostly from design publishers’ media platforms rather than his own website.
Now the decoupling of metadata being utilised vs using the actual content gets blurry here; as unlike the youtube example, the imagery these crawlers are scraping is copyrighted and belongs to both Pete (and potentially to the media platforms / photographers who took the photos).
Don’t get me wrong . . I’m not a technophobe, quite the opposite in fact. I was an early Midjourney user and love the creative freedom it offers BUT and there’s a big but . . . for people like Pete and in fact any other architect (replace architect with industrial designer, interior designer and so forth and you get the picture). When the creative products, the images of their signature works designed, built and crafted over many years, is being fed into an AI training data set . . . what we’ll see is over time, an enormous increase in derivative works and derivative references which are themselves, completely disconnected from their creators (and owners). The implications of this are deep and wide from the loss of artistic integrity, creative ownership and sovereignty to the dissolution of intellectual property rights and the monopolisation of creativity by big tech.
I’m no digital genius but presumably there are things web companies can do to reduce the risk or ease of crawlers scraping their sites. A quick search reveals a few recent 2023 articles that might provide a start point:
How to block OpenAI’s new AI-training web crawler from ingesting your data
Major websites block AI crawlers from scraping their content
We need to do more. The regulation simply cannot keep pace with the evolving technology and many aren't thinking about the ramifications every time they press /imagine on their midjourney engine. So what does this mean for the future of our creative industries? We need to be talking about this and big tech (and the platforms that feed of them) need to be held accountable.
What about the responsibilities of the personal user? Not a conversation we seem ready to have. Yet.
Other Blog Posts

Research
March 5, 24
How will declining birthrates and ageing populations shape our potential futures?


Research
May 2, 2019
Contemplating the right question is often more important than crafting the right answer.

Education
May 1, 2020
As a school student, how might you think about Earlywork as an opportunity to showcase who you are and what you’re capable of?

Story
March 6, 2023
A Science Fiction Prototyping approach to imagining our future oceans.

Research
June 5, 2023
Inputting research and information as networked knowledge nodes with supertags surfaces connections and patterns you might not otherwise pick up.

Education
September 24, 2023
What if . . we framed education as an example of chaos theory?

Education
October 17, 2023
Will school education will eventually reform as an emergent system with technology embedded as a key shaping force?



Education
April 18, 2024
What if . . instead of the failures of students, we focused on the failure of systems?. . and used that understanding to collectively reimagine education?



Research
August 20, 2024
UX (User eXperience) is in some ways, a philosophical enquiry, inviting us to question - What is this really about? What is the role of design in this moment?

Books
September 19, 2024
If we disallow radical flank activism does the right to protest mean anything at all?

Think
September 21, 2024
Thinking about Foucault in the context of women worldwide and reproductive justice


Books
November 13, 2024
When we think about development, can the concept of 'equity' be reconceptualised to connect with the context of the Global South without recovering / making visible, plural definitions of 'prosperity' or 'wellbeing'?
👋 say hello